Table of Contents of this page
Outline of Gellish
1. The Semantic Modeling Methodology
1.1 Comparison with conventional data modeling
2. The Gellish family
2.1 Gellish formal languages
2.2 The Gellish syntax, a standard data structure
3. Formalized English
3.1 Structured Formalized English
3.2 The Formalized English Dictionary
4. Usage of formalized languages
4.1 Usage as a formalized Language
4.2 Usage as a Query language
4.3 Usage as a Taxonomic Dictionary
4.4 Usage as Data Modeling language
5. Universal Databases and Messages
6. Gellish Domain Dictionaries
7. The Gellish syntax and various expression formats
8. Development, maintenance and support
9. Gellish Documentation
Outline of Gellish
Gelish and the Gellish semantic modeling methodology enable an integrated information architecture, which means that they support the integration of
- a taxonomy and ontology that contains a definition of the Gellish family of formalized languages with their syntax and semantics about concepts and kinds of relations and expressions
- dictionaries with natural language specific terminology and textual definitions which define natural language specific variants of the Gellish family of formalized languages
- knowledge about kinds
- information about individual things
- information about documents and other madia and their relations to things that are mentioned in their content.
The vocabulary of each formalized language in the family is defined in a taxonomic dictionary (which is also a language defining ontology). In that Gellish dictionary the defined concepts are related to each other in such a way that they define a natural language independent taxonomy and ontology. The language definition is available free of charge. It can be used in combination with your proprietary vocabulary and dictionary and/or in combination with one or more sections of the Gellish taxonomic dictionary. The Gellish dictionary includes natural language specific terminology and textual definitions for the concepts. This makes that the taxonomic dictionary defines formalized natural language specific variants of the Gellish family. All dictionaries in the family use the same unique identifiers (UIDs) to represent the defined concepts. The option for using prefixes to UIDs allows for using externally defined concepts and identifiers. The use of language independent UIDs for concepts enables that the expressions can be machine transformed into and presented in any other formalized natural language variant for which a formal dictionary is available. Thus Gellish Formalized English, Formalized Dutch (Formeel Nederlands), etc. are all formally defined with their own natural language terms, but share the defined concepts.
1. The Semantic Modeling Methodology
The Semantic Modeling Methodology delivers semantic information models. Such models consist of collections of expressions in which the meaning (the semantics) of the expressions is included in the expressions themselves. Thus semantic models do not require external documentation nor data models, for their interpretation. The language definition is sufficient for an unambiguous interpretation of the expressions. For that purpose, each expression includes a kind of relation that is defined in the formal language definition. The modeling methodology provides guidelines for modeling in at least the following five area’s:
- The creation of a computer interpretable Taxonomic Dictionary and language defining ontology, in which the defined concepts inherit the meaning of their supertype(s) because all concepts are arranged in a subtype-supertype hierarchy structure, which is also called a taxonomy. That dictionary also includes expressions that define other kinds of relations between concepts and expressions that specify what is by definition the case about concepts. Domain taxonomic dictionaries are typically created as extensions (or replacements of parts) of the general purpose taxonomic dictionary.
- The creation of collections of expressions of possibilities for kinds of things in a computer interpretable and reusable form.
- The expression of requirements about kinds of things, whereas such requirements are only applicable in a particular context. Such requirements can be used by software to guide designs. And when both the designs as well as the deliverables are documented in the formal language, then the requirements can also be used for automated verification of designs or of delivered products relative to those requirements.
- The expression of product and process information, including also models of complete facilities and their documentation, such as Building Information Models (BIM’s), etc. Such expressions may form integrated information models (semantic networks) that include data as well as documents about individual objects, data and documents about designs of objects as well as about realized facilities and their operation and maintenance.
- Integrated models include also a taxonomic dictionary and language definition (which enable searching for things of specified kinds as well as definitions of those kinds) and the integration with knowledge and requirements (for reuse and verification of knowledge and requirements).
- The exchange of messages, including queries, answers and statements between Gellish enabled software, for a Gellish based semantic data exchange (a real semantic database).
1.1 Comparison with conventional data modeling
Gellish enables the storage and exchange of knowledge and information in a standard universal data structure or semantic network or in expressions, using the generally applicable Gellish expression format. The Gellish Modeling Methodology improves conventional data modeling methods in various respects. Conventional data modeling, for example Object-Role Modeling (ORM) or Entity-Relationship (ER) modeling, neither provide a dictionary nor a taxonomy, nor do they provide standardized kinds of relations for expressing ideas or facts or queries, nor do they provide a standard database design or data structure. As a consequence the various models that result from the application of such conventional methods are implemented as different dedicated databases, so that every software supplier created its own database structure and every kind of message in data exchange between systems is designed with its own data structure. Such databases and messages are thus all mutually incompatible. And data that is stored in one database can only be transferred to other data stores by the creation of costly conversion and interfacing software. This problem can be solved by using the Gellish Modeling Methodology and the application of a standard Gellish formalized language and its predefined dictionary of concepts, including its standardized kinds of relations.
Conceptual data models express knowledge about kinds of things. In conventional methodologies such data models are used to design and create databases with dedicated data structures. When such knowledge is expressed in Gellish then it can be stored directly in a universal Gellish enabled database, without the need to create dedicated database structures. And then the knowledge can be used directly to guide the creation of information about individual things. This is enabled by the fact that each Gellish enabled data store consists of expressions with the same structure, whereas Gellish expressions are universally interpretable. This general applicability eliminates the need to create dedicated database designs for new applications. As a consequence it is not required anymore to convert the conceptual data models into physical data models for creating a database structure. This also opens the possibility to create reusable software that can operate on database independent queries on any Gellish data store or on the combined content of multiple Gellish data stores as well as on any Gellish exchange message.
2. The Gellish family
Each formal language in the Gellish family of formalized languages is a generally applicable and formalized subset of a natural language and uses the same universal, neutral and system independent data structure. The family of languages is designed to enable people and computers to express, store, exchange and integrate information, knowledge, requirements, queries and responses as well as the language definition itself without the need for costly data conversions for databases and interfaces between systems.
2.1 Gellish formalized languages
A Gellish formalized language is primarily defined as a structured subset of a natural language. For English the resulting language is called Gellish English. However, the formal language definitions are based on the understanding that words and phrases in natural languages are representations of concepts and things that are language independent. Therefore, each concept or thing in a Gellish formalized language is identidied by a language independent unique identifier (UID) that represents the concept or the thing as such in any of the languages of the family. In addition to that, each concept or thing can be denoted by multiple terms (‘names’, synonyms, codes and abbreviations) in any language and language community. This enables automated translation of expressions between different languages. It means that ideas that are expressed in one language do not need to be translated to other languages, as a computer is able to present such an idea in any language for which a Gellish formalized dictionary is available.
This document primarily describes formalized English, but for any other language variant you may replace the word English by the name of that other language. So, formalized English is a formalized structured subset of natural English, in the same way as the Dutch variant (Formeel Nederlands) is a subset of the Dutch language. Other formalized language variants are in a similar way subsets of other natural languages.
Formalized languages are also intended to facilitate standardization of data in databases and addition of general knowledge to support the application of logic. This can improve ‘searching and finding’ by increasing the possibilities for uniform queries in multiple databases and finding more and better results. Furthermore they are intended to provide a universal data structure for data exchange and for a generally applicable database capability. As a consequence Gellish’ main advantages over conventional information and knowledge modeling methods with free (undefined) languages are:
- Its data structure is universal and allows for extensions of its content without the need for software changes or database definition changes, whereas conventional data structures are fixed and inflexible.
- It is an open language in which any semantically correct information or knowledge can be expressed, whereas conventional database structures only allow for data for which the system was designed.
- It is defined in an extensive formal taxonomic dictionary of concepts and kinds of relations in the form of a taxonomy and ontology. This eliminates ambiguity of terminology and has as effect that data from different sources can easily be integrated, whereas for conventional databases the concepts for their definition, as well as for their content are usually ad hoc (re)defined and not selected from a standard.
- It is open for extensions and is system independent, whereas most data structures and content standards are closed, application software dependent and proprietary.
- It has automated translation capabilities, uses normal natural language terminology and expressions and do not use a separate meta language for its definition, whereas conventional systems need ad hoc translations and require the use of a separate meta language for their definition and are usually expressed in ‘programmers language’.
The Gellish formalized languages are based on the principle that knowledge and information can be expressed as a collection of relations, whereas each related thing plays its own role in a relation. Each relation has the same structure, being two or more Relation – Role – Player combinations. Groups of elementary relations can be combined into expressions (small sentences) that are basically the same in any natural language. Each such expression has in essence the form of an object-relation-object (ORO) structure, whereas in most cases the roles can remain implicit. Examples of the core of such formal language expressions (without UID’s and contextual facts) are the knowledge:
- car <can have as part a> turbine
and the requirement:
- car <shall have as part a> engine
and by information about individual things, such as:
- the Eiffel tower <is located in> Paris
- John Doe <is performer of> act-1
- Temperature of John Doe <has on scale a value greater than> 38 degC [on] 29-sep-2017
Note that the latter expression demonstrates that more complicated expressions include also other components, such as units of measure, dates of validity, and explicit roles.
Formalized expressions use standardized phrases for the kinds of relations. Those phrases are selected from the taxonomic dictionary. The expressions also use standard terms for kinds of things, which shall be selected also from the taxonomic dictionary or from a private or public domain extension of that dictionary. The names of individual things are introduced and added to an ad hoc dictionary by adding classification relations, as will be discussed elsewhere. The standardization of terminology and definitions makes languages into formalized languages and that enables that expressions can be directly integrated with other expressions (without a need for data conversion) and it makes that the expressions can be interpreted by computers.
The Gellish formalized languages are also suitable for expressing questions, answers, confirmations, denials and other communicative intents. Therefore, formal languages do not need special query languages. Data stores can thus be queried via queries that are also expressed in a formalized language. Non-Gellish data stores can be extended with a ‘mapper module’. This is further described in the section Querying data stores.
A formal taxonomic dictionary defines the concepts and terminology of the language, including also phrases that denote kinds of relations. Each concept and each kind of relation is defined as a subtype of a more general concept or kind of relation. This means that the concepts and kinds of relations are defined and arranged in a subtype-supertype hierarchy, also called a Taxonomy. This implies that the subtypes inherit the definitions and relations of their supertypes. A consequence of the Taxonomy structure is that formal expressions can be automatically verified on their consistency and grammatical correctness.
The taxonomic dictionary of kinds of relations are extensively described in the book ‘Semantic Information Modeling in a Formal Language’. For searching for specific kinds of relations or concepts and for viewing their hierarchy it is recommended to use a Gellish enabled browser.
2.2 The Gellish syntax, a standard data structure
Gellish includes a definition of a standard universal data structure for data stores and for exchange messages and queries. This means that from an information technology perspective, Gellish can be regarded as a large integrated data model that is flexible and generally applicable and can be implemented in one or more identical tables with an identical structure. It is flexible, because its application scope and semantic expression capabilities can be extended without a modification of the Gellish data structure. It is generally applicable, because it has generally applicable standard kinds of relations and embedded domain specific knowledge from various discipline areas, which kinds of relations and knowledge can be easily extended to other domain areas.
This means that Gellish expressions can be stored in universal Gellish data stores and can be exchanged between systems via Gellish messages that use a standardized Gellish interface. The universal data structure is defined in the document ‘Gellish Syntax and Contextual Facts’, available via the Gellish Download area.
3. Formalized English
3.1 Structured Formalized English
Gellish English uses terminology from natural English, nevertheless Gellish limits the language to a formally defined subset of the natural language. Therefore, it is called a formalized language that is computer interpretable. This means that Gellish English does not define its own vocabulary. Its terms are selected from the English vocabulary and included in the electronic Gellish English Taxonomic Dictionary or terms can be added via user defined Domain Dictionaries. Thus the Gellish English Dictionary provides standardized terminology that can be used as a ‘common language’ in application systems. Typically it can be used to enhance conventional data stores by standardizing their content and thus simplifying data integration and data exchange between systems. For example, the standard terminology and concept definitions can be and is used for standardizing the content of multiple implementations of systems, such as ERP, PLM and EDMS systems, that need to share or exchange data.
The formalization implies simplifications of various kinds. For example the need for using plural terms is eliminated by introduction of explicit collections, the variety of tenses such as past and future tense is eliminated by usage of explicit times, the variety of word sequences between statements and questions is eliminated by addition of explicit intentions, etc.
3.2 The Formalized English Dictionary
The Gellish Formalized English Taxonomic Dictionary is an extension of an ordinary English dictionary. The concept definitions are arranged in a subtype-supertype hierarchy, so that the concepts are arranged in a taxonomy, The dictionary is extended with additional knowledge and with further specialized subtypes. All definitions and knowledge in the dictionary is expressed as computer interpretable relationships between the concepts in the dictionary. The relations between concepts provide knowledge about what is by definition the case for the defined concepts. These additional relations make that the dictionary becomes an ontology. The relations are computer interpretable so that computer software can apply logic reasoning to find things and derive conclusions.
The standard Gellish English Taxonomic Dictionary consists of a base section (or upper ontology section) with a number of branch sections, called Domain Dictionaries.
The base section consist or the upper ontology or world ontology, includes the concept ‘anything’ and its subtypes and is not constrained to any application domain. The upper ontology includes primarily definitions of standard kinds of relations and their taxonomic hierarchy. They form the basis for making expressions. Furthermore it includes definitions of the allowed related concept and the kinds of roles that those related concepts (role players) play in those kinds of relations. That upper ontology section defines the base semantics of Gellish expressions. The upper ontology section also contains the generic concepts that are the top concepts of the hierarchy that can be further specialized in the various domain ontologies. The base section therefor acts as the integrator of the Domain Dictionaries.
Usage of Gellish requires the use of the upper ontolgy section and the extended base and may use one or more standard Gellish Domain Dictionaries, and/or may use ‘proprietary Domain Dictionaries.
Examples of standard Gellish Domain Taxonomic Dictionaries are:
- Units of measure (scales), currencies
- Activities, events and processes
- Physical objects of various kinds, such as:
- Static equipment,
- Buildings, furniture and civil items
- Systems, process units and assemblies
- Piping, protection and connection items
- Electrical and instrumentation and control equipment
- Rotating equipment, transport equipment and solids handling
- Aspects, properties, qualities and roles
- Materials of constructions, chemicals and waves
- Documents and identification, symbols and annotation
- Geographic objects
- Organisms and organizations
- Mathematics, geometry and shapes
Users and organizations are recommended to develop Domain Dictionaries for their own application domain as extensions of the Gellish dictionary.
4. Usage of formalized languages
There are basically four kinds of usage of Gellish formal languages:
- Usage as an Information Modeling language for data exchange and/or data storage
- Usage as a Query or Dialogue language
- Usage as a Dictionary or Taxonomy or Ontology
- Usage as a Language for creating dictionaries or taxonomies, and for modelling knowledge, specifying requirements, describing designs or real world objects or facilities or for managing information and documents.
4.1 Usage as a formalized language
Gellish can be used for creating Gellish based generally applicable data stores or data exchange massage. This is facilitated by the fact that Gellish enables the expression of various kinds of information using a universal data structure. For example the language enables describing various kinds of information about:
- Individual objects, their components, properties and behavior.
- Designs of facilities or real world structures or to manage information about various kinds of facilities. For example Facility Information Models or a Building Information Models (BIM).
- Business processes, transactions and other activities, such as processes that are typically described by graphical methods such as IDEF0 and DEMO.
- Physical or chemical processes, including fluid or solid product streams.
- Definitions of concepts and relations between concepts; typically for creating smart Dictionaries, Taxonomies and Ontologies.
- Knowledge that can be re-used; typically for guiding designs or for verification of designs.
- Requirements for kinds of products or standard specifications of manufacturer’s models, such as those included in product catalogs.
- Etc.
Usage of the Gellish English language for the modeling of information and knowledge implies that individual things are classified by concepts from the Gellish Dictionary, and in addition to that it implies that standard kinds of relations are used for making expressions in Formal English. The integration of the various kinds of expressions in one integrated model is illustrated by the ‘Information Architecture‘ in the following figure.
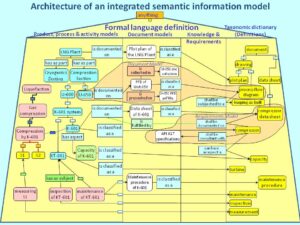
The figure illustrates the architecture of an Integrated Information Model and its main sections.
1. Products, processes and activities section.
The left hand section of the figure illustrates the core of a model of a facility. In this example the facility is a real life LNG plant in which natural gas is liquefied and which is modeled in Gellish Formal English. The facility is decomposed in components, using part-whole relations. The components have properties and are related to each other by various kinds of relation. Furthermore the components are related to processes and activities by relations that specify the way in which the components are involved in the activities or processes.
2. Documents section.
Many pieces of equipment and other facility components are related to one or more documents. The document related expressions form a collection of document models, being the second section of the Integrated Information Model. This integration of facility data and their relations to documents enable building powerful search engines for integrated product life cycle and document management systems (PLM’s and EDMS’s). It enables using the structure of the facility model to find documents about the facility components and vice versa: using documents as a user interface for finding data about the objects that are represented on the documents.
3. Dictionary section.
Each element of the facility model and each document is also related by one or more classification relations to concepts (kinds of things or ‘classes’) in the Gellish Dictionary, which is the section on the right hand side of the figure. These classification relations enable the concepts in the taxonomic dictionary and the relations between those concepts for finding documents and requirements that are applicable for components that are classified by such a concept. For example, searching for information about the concept ‘compressor’ in the dictionary will find all compressors, including things that are classified by subtypes of compressor, as well as requirements about compressors, documents about compressors, etc.
4. Possibilities and requirements.
Finally, the third section from the left in the figure illustrates the expression of knowledge about possibilities and requirements about kinds of things, in the form of relations of various kinds between concepts in the Gellish dictionary. Note: the fact that a possibility or a requirement is about a kind in the dictionary implies that the possibility or requirement is applicable to all individual things in the product and process model on the left hand side that are related to that kind via a classification relation.
The figure also illustrates that Gellish expressions can be seen as one integrated network of binary relations. If software selects one node in the network, it can easily retrieve all directly related objects and thus collect (and present) all available information about that node object.
Altogether the figure illustrates the following ways of using the Gellish language:
- For expressing knowledge about possibilities for its storage, retrieval and for exchanging knowledge between application systems.
- For expressing requirements and standard specifications for types of products and processes such as in product catalogs and for the required delivery of data and documents.
- For modeling individual facilities and their components and products (product modeling or product design) for the storage, retrieval and exchange of data and documents about them.
- For computer augmented verification of designs or for verifying information about real world objects against requirements and specifications.
- For creating Intergrated Information Models or for expressing business transactions, measured data, or any other information about facilities and their components as an integration of information from various sources in central or decentralized distributed databases.
Depending on these kinds of usage a different subset of standard Gellish relation types is applicable.
For example:
Requirements specifications mainly use kinds of relations that specify <shall be …> or <shall have…> relations between kinds of things, which are applicable for specifying relations that shall be the case. Definitions are expressed by relations that specify that something is by definition the case. Therefore, expressions in definition models include relation type phrases that begin with <has by definition…> or <is by definition…>. For example, in Gellish we can specify that a pump shall have a shaft and shall have a volumetric capacity as follows:
| Name of left hand object | Name of kind of relation | Name of right hand object |
|---|---|---|
| pump | shall have as part a | shaft |
| pump | shall have as aspect a | capacity (volume flow rate) |
Product descriptions and operational facilities mainly use kinds of relations that specify relations between individual things and classification relations that specify that an individual thing is related to a kind of thing (a class). These kinds of relations typically start with ‘is a…’ or ‘has a…’, whereas the classification relation is expressed by the phrase ‘is classified as a’. For example, the information that P-1001 is a pump that has a capacity of 5 dm3/s is described in Gellish as follows:
| Name of left hand object | Name of kind of relation | Name of right hand object |
|---|---|---|
| P-1001 | is classified as a | pump |
| P-1001 | has as aspect | capacity of P-1001 |
| capacity of P-1001 | is classified as a | capacity (volume flow rate) |
| capacity of P-1001 | is quantified on scale as | 5 |
Note that the relation types and the concepts pump, capacity (volume flow rate), 5 and dm3/s are all standard Gellish English concepts that are selected from the dictionary. The other objects, P-1001 and capacity of P-1001 are private objects that are introduced in the Gellish language by their classification relations.
The available kinds of relations and the various subsets are described in the book ‘Semantic Information Modeling in a Formalized Language’. A more extensive description of an architecture for Integrated Information Models, Building Information Models, etc. is provided in the book ‘Semantic Information Modeling Methodology’.
4.2 Usage as a Query language
Using the Gellish language for Querying a Gellish Database or for communicating in dialogues about transactions in which requests, promises, statements, etc. are expressed, requires that Gellish languages are suitable as a query language or as a business communication language.
There are two main characteristics of a query language:
1. it requires that questions can be distinguished from statements 2. it requires the use of (implicit or explicit) unknowns
Questions:
An expression of a question usually has a word sequence (grammatical structure) that differs from a statement. For example, in English the question ‘is the Eiffel tower located in Paris’ has a word sequence that differs from the statement ‘the Eiffel tower is located in Paris’. From that word sequence a reader can infer that it is a question or a statement. ‘Speech act theory’ (John Searle) delivered the insight that the variation in grammatical structure of expressions in languages can be eliminated when a ‘communicative intent’ is added to an expression. This implies that in a formal language we can use one grammatical structure, that of statements and add an ‘intention’ to each expression. This implies that the expression ‘question: the Eiffel tower is located in Paris’ will be interpreted correctly as a question. For this reason every expression in Gellish has an intention. By default the intention is ‘statement’. Questions have as intention ‘question’, whereas the grammatical structure of statements and questions are the same. Note that this enables computer dialogues by expressing promises, denials, commands, confirmations, etc. by just adding the applicable intention to a Gellish expression.
Unknowns:
Expressing conditions for searching unknown objects requires that the unknowns have an identity. Therefore, unknowns are allowed in Gellish questions. They are objects that have any name that does not appear in the dictionary, nor are they ad hoc used in statements. Example of names of unknowns can be just a question mark or terms such as what, which, who or what-1, what-2, etc. Software will allocate UIDs to unknown objects in a range between 1 and 100. Unknowns can be used in expressions of questions in the same way as names of known things are used. Thus a question will be expressed with an expression model that uses the Gellish languages in the same way as the expression of statements. Search for answers in therefore a matter of pattern recognition: which known objects can be substituted for the unknown and thus satisfy the expressions of the query.
4.3 Usage as a Dictionary and/or Taxonomy
Formal English is defined in the electronic Gellish Formal English Taxonomic Dictionary. That dictionary can be used either in stand-alone mode, for example via Gellish Dictionary browser software (such as the Gellish Browser or Communicator ) or by incorporating the dictionary (or a subset of it) as standard reference data in one or more application systems.
Examples of usage of the Gellish English Dictionary are:
- Usage as a classification system for standardization of data and common terminology in order to harmonize data in databases in various systems in a company or in an industry. For example, standardize the classification of equipment and their properties, or to standardize document types e.g. in ERP systems, design systems, maintenance systems or document management system.
- Usage for the standardization of keywords in document management systems.
- Usage for improving search engines for retrieval of information by using the Gellish dictionary terms and synonyms (with possible private extensions) as the basis for allocation of keywords and for the keyword search, while using the taxonomy (subtype-supertype hierarchy) of kinds of things (classes) in the Taxonomy to find also information that is classified by subtypes of things.
Usage of the Gellish English dictionary may include not only usage of names and textual definitions, but possibly also the usage of the subtype-supertype hierarchy relations and possibly also the facts that express what is by definition the case for the defined concepts.
Applications that use only the dictionary may select from the Gellish Dictionary Database only the expressions that define concepts and the expressions that define synonym names for those concepts. Those expressions can be recognized on the kinds of relations which they use, because those expressions contain only relation types that are indicated by the following Gellish phrases:
- is a kind of (or its synonym ‘is a specialization of’) – Such an expression defines a concept as being a subtype of another concept and provides a textual definition for the concept.
- is a qualitative subtype of – Such an expression defines that a qualitative or quantitative aspect <is a qualitative subtype of> a conceptual aspect. For example, red <is a qualitative subtype of> color, and ASTM 317 <is a qualitative subtype of> stainless steel.
- is a synonym of
- is an abbreviation of
These relation types are the main standard relation types that are used to extend the Dictionary with the definition of additional concepts. Guidelines for the extension of the Dictionary are given in the book ‘Semantic Information Modeling Methodology. A summary of those guidelines is provided in this wiki on the page rules for proper definitions of new concepts and rules for names of concepts.
If you need only a subset of the concepts in the Dictionary then it is nevertheless recommended to import the whole taxonomy, but to mark only those concepts that will be made visible to users. This will simplify the upgrading to newer releases of the Gellish English Dictionary and will support the inclusion of private extensions.
4.4 Usage as Data Modeling language
Using the Gellish English language for specification of data models, thus using it as a data modeling language implies specifying what can be the case and what shall be the case in information models in a particular domain (universe of discourse). Note that languages in general do not specify what can be the case, but only specify what are semantically correct expressions. Therefore, for a Gellish based database it is not required to specify on beforehand what data can or may be entered in the database. However in conventional databases the data models constrains what can be expressed and the validation rules of the data models prescribes what shall be expressed once something is entered. For this reason Gellish distinguishes between a language defining ontology and possibilities and requirements expressing ontologies. Modeling possibilities and requirements can be used as constraints in a particular application environment by specifying such an environment as the ‘validity context’. For this reason Gellish expressions can be accompanied by a ‘validity context’. Thus by specifying what can or shall be the case in a particular validity context the Gellish language can be used for creating conventional data models. The creation of data models is the same as modeling possibilities (knowledge) and requirements in Gellish.
The resulting Gellish English conceptual data models are ordinary Gellish information models that are expressed using the kinds of relations that are standardized in Gellish and that use the concepts that are already defined in the Gellish Dictionary or their proprietary extensions where necessary. Data models expressed in Gellish have several advantages over conventional ways to express them. For example, Gellish data models are expressed in a computer interpretable form and can be integrated with other data, they are extensible and they can be directly used by software to guide the creation of data instances, without the need for the design of a physical data model or without the need for modification of the database definition or structure.
5. Universal Databases and Messages
Gellish Databases are universal semantic databases that enable the storage of virtually any data. They can contain the equivalent of any number of database tables. Gellish Database systems have a universal structure, which can be represented as a network. This makes them generally applicable and extendable without the need for redefining their data structure (data model). All Gellish databases have as common characteristic that they enable to store any knowledge and information that can be expressed in the Gellish English language. They also have as common characteristic that they have the capability to import and integrate data that are expressed in the form of the content of other Gellish Expression Tables.
Gellish Messages and Queries can be exchanged between computer systems, using a standard data exchange protocol, such as the SOAP protocol or the REST protocol. Such a message consists of an envelop, a header and a body. The body is formed by a collection of Gellish expressions, similar to rows in a Gellish Expression Table. When the SOAP protocol is used, the Gellish message or Query is exchanged in XML format. Such messages can be sent as a query or as a response in peer to peer networks of Gellish enabled applications to query a central database or a decentralized distributed database.
Data integration requires the use of a common language, which includes a common dictionary of concepts and kinds of relation. Therefore it is important that users of Gellish should have the discipline to obey the rules for correct Gellish. You should carefully evaluate whether new concepts, especially kinds of relation, are really needed or that existing concepts are already available in the Gellish Dictionary. If you think that a new concept is really required, then you are strongly recommended to provide feedback and to propose your extensions as enhancements of the Gellish Dictionary-Taxonomy.
6. Gellish Domain Dictionaries
Organizations typically use their own terminology in systems and for their proprietary product types. In that way, organization form their ‘language community‘. Part of the terminology of such a community will overlap with the world outside the community by using synonyms, and partly the community defined their own concepts. For example, product names or codes for the product types that are manufactured by an organization are proprietary terminology that can be included in a company specific domain dictionary. This is the main reason why organizations may maintain their own proprietary terminology. This section describes how such concepts and terminology relate to Gellish and its taxonomic dictionary.
Using Gellish implies that at least the base ontology section is used, because that defines the core of the Gellish language (its ‘Upper Ontology’). In addition to that it may include using part or all of the other Domain Dictionaries of the full Gellish Taxonomic Dictionary, possibly extended with proprietary defined concepts or Domain Taxonomic Dictionaries. For example, parties may wish to use the Civil Engineering Domain Dictionary and the Building and Construction Domain Dictionary (in Dutch or English) and the Units of Measures Domain Dictionary or nothing at all of the remainder of the Gellish English Taxonomic Dictionary.
When parties want to use Gellish and want to develop and use their own (proprietary) Domain Taxonomic Dictionary, then they need to understand how to combine their stuff with the concepts that are defined in the Gellish dictionary.
The Gellish Modeling Methodology provides guidelines on how to create such Gellish compliant Domain Taxonomic Dictionaries and how to manage the Unique Identifiers (UIDs).
The use of proprietary Gellish Domain Dictionaries is convenient and supports adoption of the methodology, because of the familiarity of its users with their own terminology. However, the use of proprietary Gellish Domain Dictionaries has two main risks:
- Your Domain Dictionary may overlap or conflict with other Gellish Domain Dictionaries. This means that data integration may still be a problem when you want to communicate with systems that are not familiar with your Domain Dictionary. So you cannot simply integrate data from other parties that use a different Domain Dictionary.
- Your Domain Dictionary may contain concepts that are not subtypes of the concepts in the Gellish base ontology section. This is against one of the basic Gellish rules and causes that the correctness and consistency of the Gellish expressions cannot be verified.
For example, not using the full Gellish Taxonomic Dictionary means that the power of the Gellish taxonomy is not utilized and thus that nothing is used of the benefits of the inheritance capabilities, searching on subtypes, application of logic reasoning and semantic verification possibilities), the synonyms, the definitions and the distinctions between objects and their roles, the standard units of measure and their conversions, etc.
To avoid these risks of overlap or isolation it is recommended to define mapping expressions that include (only) synonym relations between your own terminology and equivalent names in the Gellish Dictionary that denote the same concepts (the same UID). This is especially useful when your domain dictionary or the terminology in one or more of your systems is a subset (or translation) of the standard Gellish English Dictionary.
Synonyms can be defined as part of an ordinary collection of Gellish expressions that is part of your Domain Dictionary. Such synonym expressions should use your Domain name as ‘Language Community’ and should contain subtypes of the alias kind of relation for relating your names to the names from the standard Gellish Dictionary, whereas your concepts are identified by the UIDs of the concepts in the standard Gellish Dictionary. Examples of synonym expressions (mapping expressions) are:
| Language | Language community | Name of left hand object | Name of relation type | Name of right hand object |
|---|---|---|---|---|
| English | SAP | ME_PUM | is a synonym of | pump |
| English | SAP | P | is an abbreviation of | pump |
| German | SAP | Pumpe | is a translation of | pump |
It is also possible to state that a name in your context <is the same as> the same name in the general context of the standard Gellish Dictionary.
You can then add proprietary subtype concepts where necessary.
Examples of such Synonym expressions are available for the ISO 15926-4 Domain Dictionary terminology. Several companies developed such synonyms in collections of Gellish expressions. For example, synonym tables were made for terminology in various database implementations, such as equipment types and property types in various SAP implementations for maintenance and inspection. Implicitly in such cases the synonym expressions indicates which subset of the standard Gellish Dictionary is used in the application.
A possible implementation could then even use the full Gellish taxonomic dictionary at the background, while the software only shows the proprietary synonyms of the subset to the users, together with possible proprietary extensions.
7. The Gellish syntax and various expression formats
The structure of Gellish expressions, their syntax, distinguishes between the expression of ideas and the contextual facts about each idea. A idea is for example the statement that Berlin is the capital of Germany. Contextual facts about this idea are among others the language of the name of a defined concept such as Berlin is a name in English, the status of the statement as being accepted, the timing since when that is the case, who created the idea, etc.
Expression of an idea
An expression of any idea is based on the observation that each idea can be expressed as a collection of one or more binary relations (‘basic semantic units’). For practical purposes and keeping close to natural languages, some binary relations are combined into composed expressions as will be clarified later. As a consequence expressions in Gellish consists of a number of elements:
- The idea itself. Note that the idea itself is language independent, because the fact that Berlin is the capitol of Germany is independent of the language in which that idea is expressed. Therefore, each idea is represented throughout all Gellish language variants by a language independent unique identifier (UID) (say 1). Usually ideas don’t have a name, but sometimes in user interfaces they are denoted by a phrase.
- The two concepts that related in a binary relation. In the example they are denoted in English by the names Berlin and Germany . Each of them is also represented by its own UID (2 and 3).
- The relation between the two related concepts is classified by a kind of relation. In the example that kind of relation is denoted by the phrase ‘is the capitol of’, whereas that kind of relation has its own UID (4). Furthermore, it is possible that for the expression of the same idea an inverse phrase is used while inverting the sequence of the related objects. Therefore, the ‘phrase type UID’ (5) represents the used phrase in a natural language independent way.
- The roles that are played by the related objects are usually implicit, but those roles need to be explicit e.g. when constraints on objects in particular roles are applicable. Those roles have their own UIDs (6 and 7) as well as their own names. In the example, the names are ‘capitol’ and something like ‘possessor of capital’.
- The kind of intention, being ‘statement’ in the example, also has its own UID (8).
- The units of measure. Sometimes an expression consists of a quantification of a physical property by a number on a scale. In those cases the relation is classified twice. The first classification is by the kind of relation between the property and the number (such as ‘is equal to’ or ‘is greater than’) this is covered by the above described kind of relation UID (4). The second classification of the relation is by the method that is used for creating the relation between the property and the number. Such a method is usually called a scale or a unit of measure. For example, a temperature may be quantified by the number 60 using the method invented by Fahrenheit, usually denoted by the scale or unit of measure ‘degree F’. Such a scale has its own UID (9).
This causes that a full expression of any one idea in Gellish consists of maximally 9 UIDs and 8 denoting terms (names). Note that the expression can be compressed to a list of UIDs only after the terms are properly included in a dictionary that connects UIDs to terms in various contets. In the Gellish expression format these 16 values are stored in a table of which each column has its own standardized ID. This enables to arrange the columns in any sequence that is convenient for a user and enables to use subsets of columns as and when required.
An example of a tabular form expressions in Gellish Expression format is given in the ‘Example of a road. An elucidation of its content in pdf format is also provided.
Contextual facts For a correct interpretation of the meaning of an expression of an idea it is often important to know contextual facts about the expression of an idea. In Gellish the expression of each idea is therefore accompanied by a number of contextual facts. That is the reason why a Gellish Database table consists of a large number of standard columns, although the expression of a main fact basically only requires 3 columns.
The idea as well as all those contextual facts can be expressed on one row in the Gellish expression format. However, they can also be stored differently, for example in a triple store or in an object oriented database.
Users may wish to ignore some or all of the contextual facts (or even some columns for the expression of the basic semantic units) in their implementation. For that reason standard subsets of columns are defined. The smallest subset is a triple, which includes a left hand object name, a relation type name and a right hand object name. (In RDF those three components are called subject, property and object). Applications that do not require the implementation of the full set of auxiliary facts can use one of the subsets.
Each subset table of the Gellish Expression format can be represented as a file in Excel xls(s) format, but the table may also be expressed e.g. in CSV or JSON. It may also be expressed in XML or RDF / Notation 3 using an XML Schema definition.
The full Gellish syntax and all contextual facts are described in detail in the document ‘the Gellish Syntax and Contextual Facts‘.
8. Ownership
Gellish and the various members of the family of formal languages, such as Formalized English and Formalized Dutch, are International Industry Standards that are owned by Gellish.net, founded by Dr. Ir. Andries van Renssen, who previously developed information management standards for Shell and got his PhD on the subject at Delft University of Technology in 2005. Gellish is an improvement and extension of ISO 10303-221 and ISO 15926 and it is compliant with ISO 16354. The Gellish taxonomic dictionary includes concepts that also appear in international standards, and is developed by van Renssen who guided and managed a number of teams of domain experts from various international companies.
9. Gellish Documentation
For the description of some core concepts of Gellish see the next paragraph about basic principles of Gellish. Explanation of the interpretation by software of Gellish expressions is given on the section Developing Gellish enabled software.
The Downloads page of this website contains the Gellish English definition as well as a number of documents about Gellish,